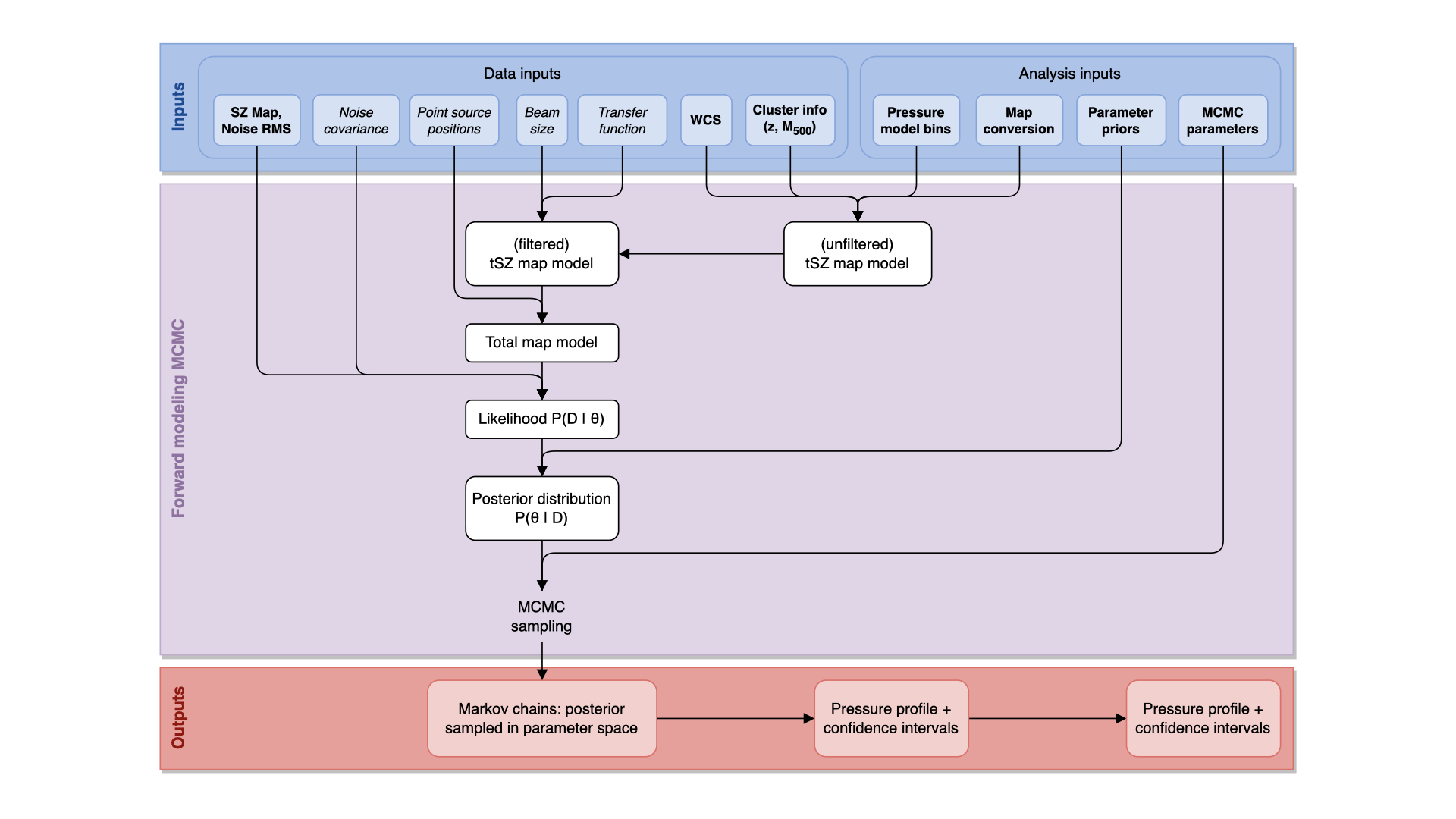
Software
Doing research at scale requires software that is fast, correct, and maintainable - and building that software is something I deeply care about. Across my projects, I have written production-quality scientific libraries adopted by collaborations well beyond my own group.
My software work spans the full stack: from low-level numerical kernels (GPU-accelerated JAX operations) to high-level analysis pipelines with clean APIs, comprehensive documentation, and automated CI/CD. A recurring theme is performance engineering: identifying computational bottlenecks and redesigning algorithms to achieve order-of-magnitude speedups or better, without sacrificing correctness or generality.
All software is open-source, hosted on GitHub, and accompanied by documentation, example notebooks, and automated test suites - not as an afterthought, but as a core part of the development process.